


CSLMs (Crazy Small Language Models) have arrived: you read it here first.
”D3: A Small Language Model for Drug-Drug Interaction prediction and comparison with Large Language Models” introduces a 70 MILLION (yes, six zeros, not nine) Llama-like model that is on par with Llama-3.1 70B for drug interaction prediction. It was trained and fine-tuned from scratch in 2.5 hours on a single A100.
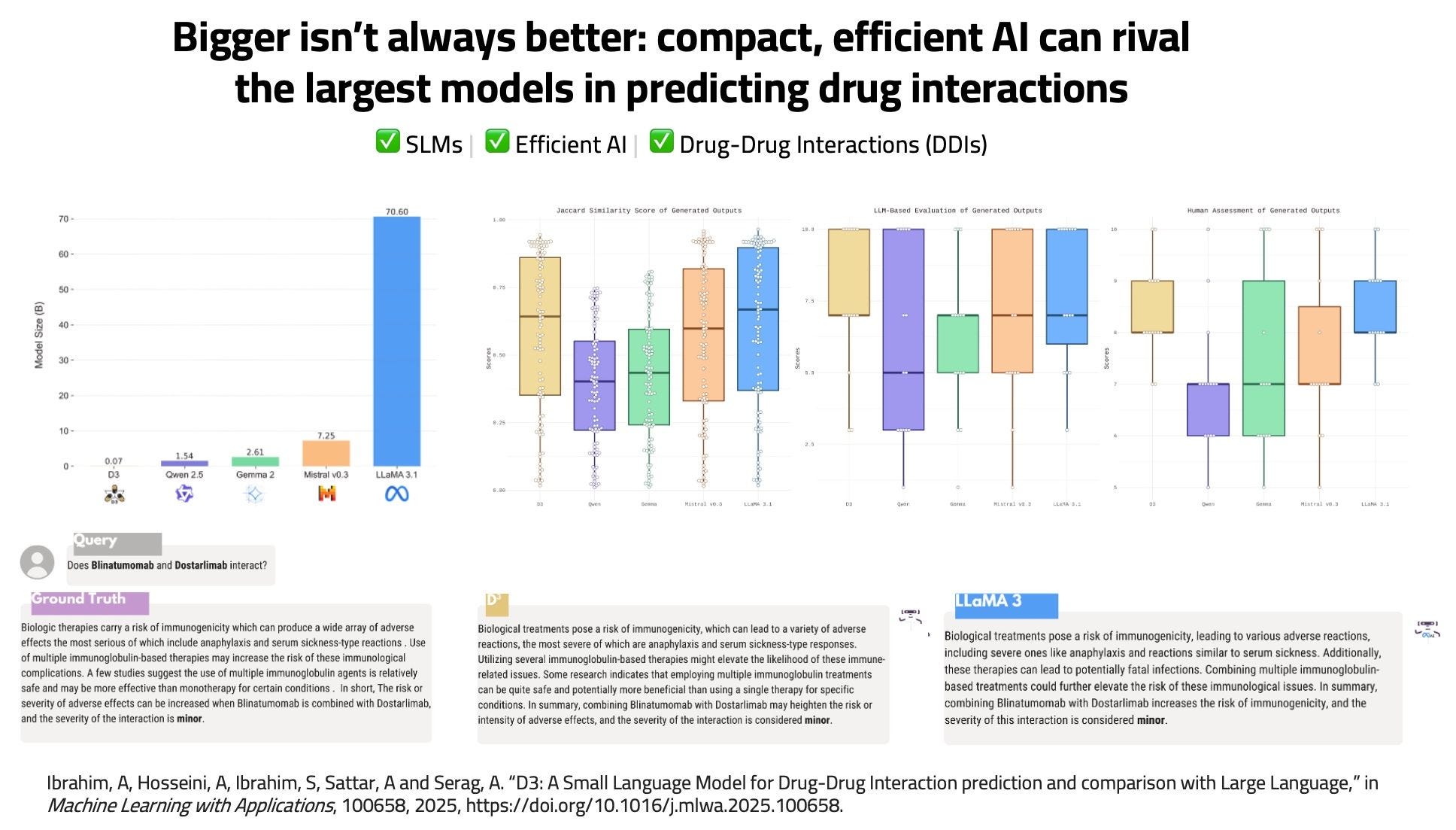
This research is yet another proof that it's reasonably easy to build excellent - and even SOTA - models at a tiny fraction of the time, cost, and energy required by larger models. All it takes is a well-defined business problem, some good quality data, and a mind immune to LLM marketing bullshit.
Here's what I wrote in October 2021 as I joined Hugging Face:
"Large language model size has been increasing 10x every year for the last few years. This is starting to look like another Moore's Law. We've been there before, and we should know that this road leads to diminishing returns, higher cost, more complexity, and new risks. Exponentials tend not to end well. Remember Meltdown and Spectre? Do we want to find out what that looks like for AI? Instead of chasing trillion-parameter models (place your bets), wouldn't we all be better off if we built practical and efficient solutions that all developers could use to solve real-world problems?"
Those of you who paid attention instead of spending silly money on prompt engineering bootcamps, OpenAI PoCs, and GPU clusters are quite likely to be in a good spot right now 😉
More projects like this one, please. Share them, tag me, and I'll be happy to promote them. If you need help building these, please ping me and let's discuss how Arcee AI can assist.